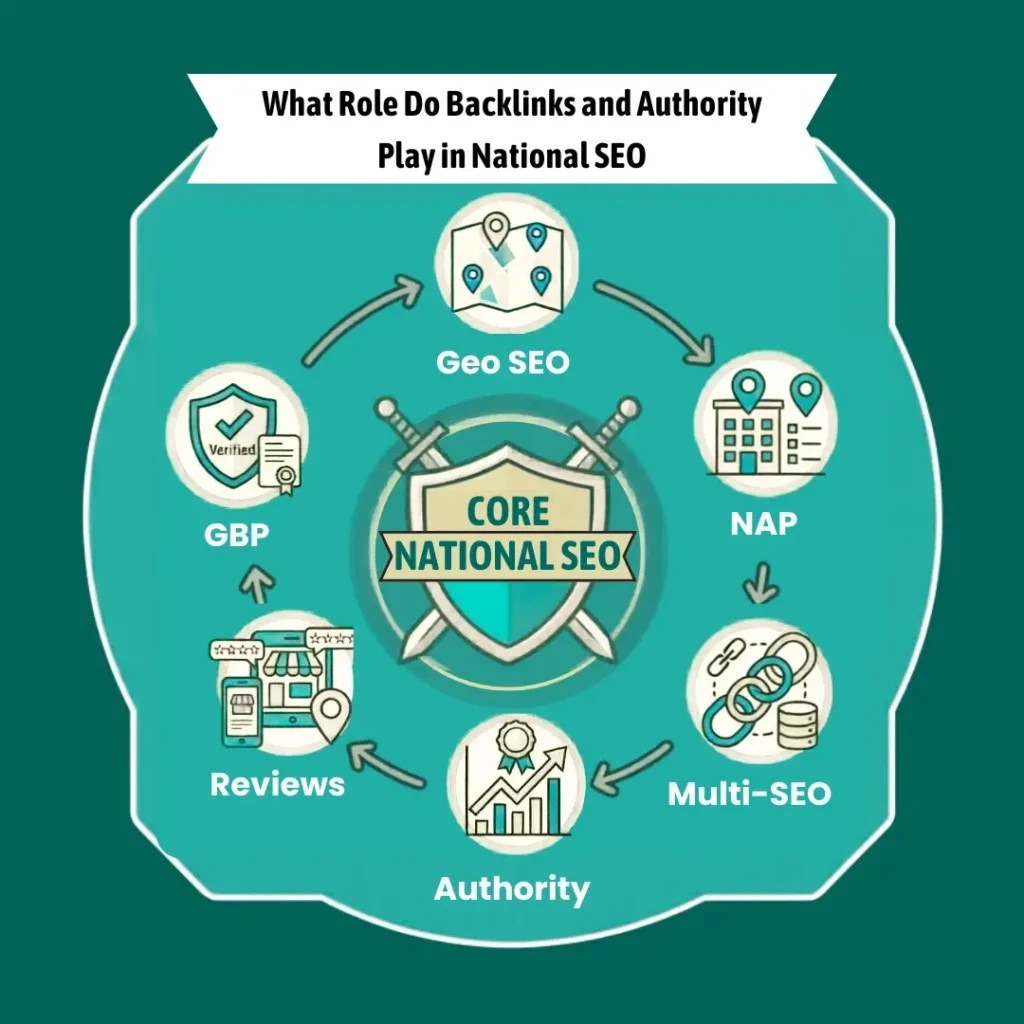




Introduction
Artificial intelligence has changed the speed of publishing. One prompt can produce hundreds of pages in minutes. A team that once needed months to build a knowledge base can now generate it in a single week.
That scale creates a new technical SEO problem. Search engines cannot crawl everything at the same speed as AI can produce it. When large sites expand too quickly, Googlebot becomes selective. Some pages are crawled. Others are discovered but ignored. A part may never reach the index. This is where crawl budget optimisation becomes critical.
This article explores the technical framework needed to manage crawlability and indexation. Especially when AI content grows at enterprise scale.
Table of Contents
Why AI Content Breaks Traditional Crawl Logic
AI has removed the traditional limit of content production. But search engines still operate under resource constraints. This mismatch produces what many technical SEO teams now call the scaling paradox. A website can generate more content than search engines are willing to crawl.
The Velocity Gap
Large language models produce pages almost instantly. A publishing pipeline can generate thousands of pages in a single batch. Search engines move slower.
Google assigns each website a crawl capacity. This capacity depends on server performance, historical trust, and content quality signals. When the number of new URLs grows faster than Google’s crawl capacity, a gap forms. Pages accumulate faster than they are processed.
The result is a delay in indexation issues in large websites. Even strong domains experience this issue. The issue happens once their AI pipelines start generating pages at a large scale.
Defining "Crawl Waste" in the AI Context
Crawl waste is not a new concept. In the past, it referred to broken links, duplicate pages, or endless pagination. AI changes the definition.
Large AI systems often create clusters of content that offer little more value. These clusters may target similar queries or repeat ideas across slightly different URLs. From a crawler’s perspective, these pages consume resources but add minimal value.
Examples include:
- Slightly rewritten AI summaries
- Near-duplicate location pages
- Thin topic variations generated in bulk
If bots spend time crawling these pages, they may skip more valuable content. In large AI ecosystems, crawl waste often becomes the primary barrier to indexation.
The Relationship Between Crawl Rate and Host Load
Search engines also protect websites from overload. Googlebot measures how quickly a server responds. If response times increase, the crawler reduces its activity to prevent damage.
AI publishing pipelines can unintentionally stress infrastructure. Thousands of new URLs may trigger heavy database queries or dynamic rendering processes. When servers slow down, the crawl rate drops.
Technical SEO teams must thus track Google crawling efficiency optimisation. Efficient hosting, caching, and resource management help maintain a stable crawl rate. This happens even during large publishing bursts.
Diagnosing Indexation Friction in Enterprise AI Ecosystems
Many large websites assume Google will eventually index their pages. In reality, search engines often discard large portions of AI-generated content before indexing. Understanding where this breakdown happens is the first step toward solving it.
Analysing the "Discovered But Not Indexed" Bottleneck
Google Search Console provides an important signal: the “Discovered but Not Indexed” status. This message appears when Google knows a page exists but decides not to crawl it yet.
For AI-heavy sites, this status can grow rapidly. Hundreds or thousands of pages may sit in this category for weeks. Two different causes usually appear.
The first is quality filtering. If Google suspects a page adds less value, it may delay crawling. This happens while evaluating signals from similar pages.
The second is the crawl budget optimisation. In this case, Google cannot process every URL. Distinguishing between these scenarios is important. Quality issues need content improvements. Budget limitations need technical optimisation. Large enterprise sites face another complication.
Research shows that 40% crawl activity targets non-canonical or duplicate URLs. That means half of the crawler resources may be spent on pages that should never have been crawled. Correcting these structural problems can improve indexation rates.
Log File Analysis: The "Ground Truth" for Large-Scale Sites
Search Console provides useful summaries. Yet, it does not show the full behaviour of search engine bots. Log file analysis fills this gap.
Server logs record every request made to a website. When analysed correctly, they reveal exactly how bots move across a domain. Technical SEO teams can identify:
- Which sections of the site receive frequent crawls
- Which pages are ignored entirely
- How quickly bots revisit important URLs
Log analysis also exposes a common issue in AI-driven platforms. Bot traps occur when designed navigation systems generate infinite URL combinations.
Faceted filters, dynamic search pages, or AI-generated archives create thousands of different URLs. A crawler entering these systems may continue exploring them indefinitely. This behaviour drains crawl budget while providing no new information.
Log data often reveals these traps long before other tools detect them.
Crawl Budget Optimisation Fixes Technical Architecture
Once crawl inefficiencies become visible, technical improvements can restore balance. Architecture decisions determine whether crawlers move smooth through a site.
Pruning the AI Branch: Strategic Use of noindex and disallow
Not every AI-generated page deserves indexation. Some pages exist only to assist users. These might include filters, navigation hubs, or contextual help pages.
Although they support the user experience, they do not belong in search results. These are often called helper pages. Technical SEO teams should prevent such pages from consuming crawl resources. Two directives help manage this process.
The noindex tag allows bots to crawl a page but prevents it from appearing in search results. This option is useful when pages provide context. But it should not compete with primary content.
The disallow rule inside robots.txt blocks crawling completely. Both approaches reduce unnecessary crawler activity. Another useful tactic is creating crawl gates. These are deliberate restrictions that stop bots from entering sections. Such sections are those where infinite URL generation may occur. Without these barriers, AI archive systems can overwhelm crawlers.
Optimising the Sitemaps of Infinite Sites
XML sitemaps play a major role in guiding search engines across large domains. Yet, many large AI sites treat sitemaps as simple lists of URLs. This approach fails once page counts reach hundreds of thousands.
Sitemap structure should mirror content structure.
Segmenting sitemaps by content, topic clusters, or AI content allows tracking indexation. If one batch performs poorly, technical teams can isolate the issue quickly. Another important signal inside sitemaps is the lastmod tag.
This tag indicates when a page was last updated. For AI archives that rarely change, the tag should remain static. This signals to Google that the content does not require frequent crawling. Meanwhile, recently generated pages should display updated timestamps.
This encourages bots to prioritise them. Proper sitemap management directs crawl attention toward important sections of a large site.
Moving to Server-Side Rendering (SSR) for AI Content
Rendering strategy strongly influences crawl efficiency. Client-side rendering has become common in modern web applications. In this model, a browser loads a basic HTML shell. And it executes JavaScript to generate page content.
Search engine bots can process JavaScript, but the process consumes significant resources.
On small websites, this cost is manageable. On AI-driven platforms with thousands of pages, it becomes expensive. Server-side rendering solves this problem.
Instead of requiring bots to execute scripts, the server delivers rendered HTML immediately. This reduces processing time and allows crawlers to move through pages more quickly. The concept can be illustrated with a simple formula:
[ \text{Render Time} \times \text{Page Count} = \text{Crawl Depletion Rate} ]
If rendering each page takes time, large websites can exhaust their crawl allocation. Reducing render time through server-side delivery protects crawl capacity.
Advanced Indexation Strategies: Beyond the Basics
Once architecture and crawl efficiency improve, advanced indexation tactics can speed up discovery. These strategies shift the process from passive waiting to active signalling.
How Google Evaluates Crawability of AI-Generated Sites
Crawl budget optimisation is not only about technical efficiency. Search engines also check whether a page deserves to be indexed in the first place. As AI-generated content grows across the web, Google has become more selective. It is selective about what it processes and stores.
Often, pages are not skipped because of crawl limits. They are skipped because the system predicts a low value. It considers:
- Helpful Content Systems and AI Pages
- Entity Depth and Topical Authority
- AI Content Monitoring Through Engagement Signals
Leveraging the Google Indexing API and IndexNow
Traditionally, search engines discover pages by following links. This process is known as pull discovery. Modern indexing systems allow a different approach.
Push indexing. The Google Indexing API allows websites to notify Google when new content appears. Although designed for job listings, some large platforms use it for accelerated workflows.
IndexNow offers a similar mechanism supported by several search engines. Instead of waiting for crawlers to revisit a site, content updates can be done instantly. But these systems need careful management.
Sending thousands of requests at once may trigger throttling. Batching updates into structured groups helps maintain consistent indexing performance.
The "Hub and Spoke" Internal Linking Model
Internal linking remains one of the strongest signals guiding crawler movement. For large AI ecosystems, random linking structures rarely perform well. Bots may miss important pages or spend time exploring low-priority content.
A hub and spoke model offers a clearer structure. In this model, central hub pages represent major topics. Supporting pages link back to these hubs and also connect to related cluster content.
This architecture creates predictable crawl paths. Bots reach important sections quickly while still discovering deeper content layers. AI systems can even generate internal linking patterns automatically. When configured, these systems connect new pages to established topic hubs. This happens immediately after publication.
This approach also prevents orphan pages. Orphan pages have no internal links pointing toward them. Without links, search engines may never discover them. Programmatic SEO often generates thousands of such pages unless linking structures are enforced.
Managing Thin Content Pages: The Post-Generation Content Audit
Large AI sites do not remain static. Content continues growing long after the initial launch. Without regular audits, unused or underperforming pages accumulate. These pages are often called junk pages.
Thin content pages are URLs that receive little traffic and attract no links. It shows no meaningful engagement signals. Although they appear harmless, they consume crawl resources.
Identifying these pages requires performance monitoring over time. A common threshold is ninety days without meaningful user activity. Once identified, each page should enter the Merge framework.
If the topic still matters, the content may be merged with a stronger page covering the same subject. If the page offers no lasting value, it should be removed or redirected. This process recovers crawl budget and concentrates ranking signals on stronger content. Some technical SEO teams also track a metric known as the crawl health score.
This internal KPI measures how efficiently crawlers move through the website. It may include factors such as duplicate rate, crawl depth, and indexation success. Improving this score often correlates with better search visibility across large domains.
Summary: Scaling Responsibly in the Age of Generative Search
AI has made large-scale publishing possible for almost any organisation. Yet search engines still operate under resource limits. For this reason, efficiency matters more than volume.
Websites that generate thousands of pages without managing crawl paths experience poor indexation. Valuable content may remain hidden simply because bots cannot process everything.
Technical SEO teams must therefore treat crawlability for AI-generated sites with discipline. Certain factors contribute to healthier crawling behaviour. It includes monitoring server logs, duplicate URLs, internal links, and pruning low-value content.
Looking ahead, search engines continue refining their quality systems. Google’s Helpful Content framework already evaluates whether pages genuinely assist users. Sites that publish high volumes of low-value AI pages see less crawl attention over time. The websites that master both will gain a significant advantage in generative search.
Frequently Asked Questions
1. What is crawl budget and why is it important for large AI-generated content sites?
Crawl budget refers to the number of pages a search engine bot crawls on a website within a given time. For large AI-generated sites, managing it ensures important pages are discovered and indexed.
2. Why do many AI-generated pages remain “Discovered – Currently Not Indexed”?
This usually happens when Google finds the URL but delays crawling due to limited crawl budget or low perceived value.
3. How can technical SEO improve crawlability on large websites?
Technical SEO improves crawlability by fixing duplicate URLs, optimising internal linking, and managing sitemaps. These actions help search engine bots navigate the site efficiently.
4. Do AI-generated pages harm crawl budget?
AI-generated pages do not automatically harm crawl budget if they provide useful and unique information. Problems arise when thin content forces search engines to waste crawl resources.
5. How often should large AI websites audit their content for crawl efficiency?
Large websites should perform crawl and content audits at least every few months. Regular audits help identify junk pages, duplicate URLs, and other issues.